
Large Language Models (LLMs) have revolutionized fields from natural language understanding to reasoning and code generation. However, pushing their reasoning ability to truly superhuman levels has been limited by the need for massive, high-quality, human-annotated datasets. A team of researchers from Tencent AI Seattle Lab, Washington University, the University of Maryland, and the University of Texas have proposed R-Zero, a framework designed to train reasoning LLMs that can self-evolve without relying on external data labels.
Beyond Human-Curated Data
Most progress in LLM reasoning is tethered to datasets laboriously curated by humans, an approach that is resource-intensive and fundamentally limited by human knowledge. Even label-free methods using LLMs’ own outputs for reward signals still depend on existing collections of unsolved tasks or problems. These dependencies bottleneck scalability and hinder the dream of open-ended AI reasoning beyond human capabilities.
R-Zero: Self-Evolution from Zero Data
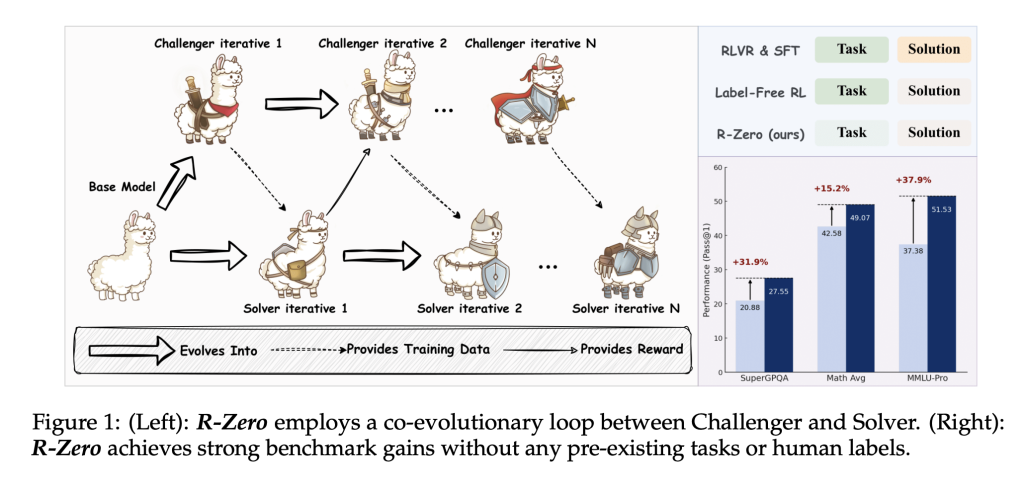
R-Zero forges a novel path by entirely removing the reliance on external tasks and labels. Instead, it introduces a co-evolutionary dynamic between two instances of a base model:
- Challenger: Responsible for creating new, challenging reasoning tasks near the edge of the Solver’s capability.
- Solver: Trained to solve increasingly difficult problems posed by the Challenger, improving iteratively.
This synergy enables the curriculum—the set of training data—to be self-generated and adapted continuously to the model’s evolving strengths and weaknesses. The process works as follows:
- Challenger Training: Trained via reinforcement learning (specifically Group Relative Policy Optimization [GRPO]), it generates diverse, hard-to-solve questions. The reward signal for each question is based on the Solver’s uncertainty: highest when Solver’s answers are maximally inconsistent (empirical accuracy approaches 50%).
- Solver Training: Solver is fine-tuned on the Challenger’s curated problems. Pseudo-labels (answers) are determined by majority vote among Solver’s own responses. Only questions with answers neither too consistent nor too scattered (i.e., in an informative band) are used for training.
- Iterative Loop: Challenger and Solver alternate roles, co-evolving over several rounds, progressively improving reasoning abilities without human intervention.
Key Technical Innovations
- Group Relative Policy Optimization (GRPO)
GRPO is a reinforcement learning algorithm that normalizes the reward for each generated answer relative to the group of responses for the same prompt. This method efficiently fine-tunes policy LLMs without a separate value function. - Uncertainty-Driven Curriculum
The Challenger is rewarded for generating problems at the Solver’s frontier—neither too easy nor impossible. The reward function peaks for tasks where the Solver achieves 50% accuracy, maximizing learning efficiency per theoretical analysis. - Repetition Penalty and Format Checks
To guarantee diverse and well-structured training data, a repetition penalty discourages similar questions within a batch, and strict format checks ensure data quality. - Pseudo-Label Quality Control
Only question-answer pairs with intermediate answer consistency are used for training, filtering out ambiguous or ill-posed problems and calibrating label accuracy.

Empirical Performance
Mathematical Reasoning Benchmarks
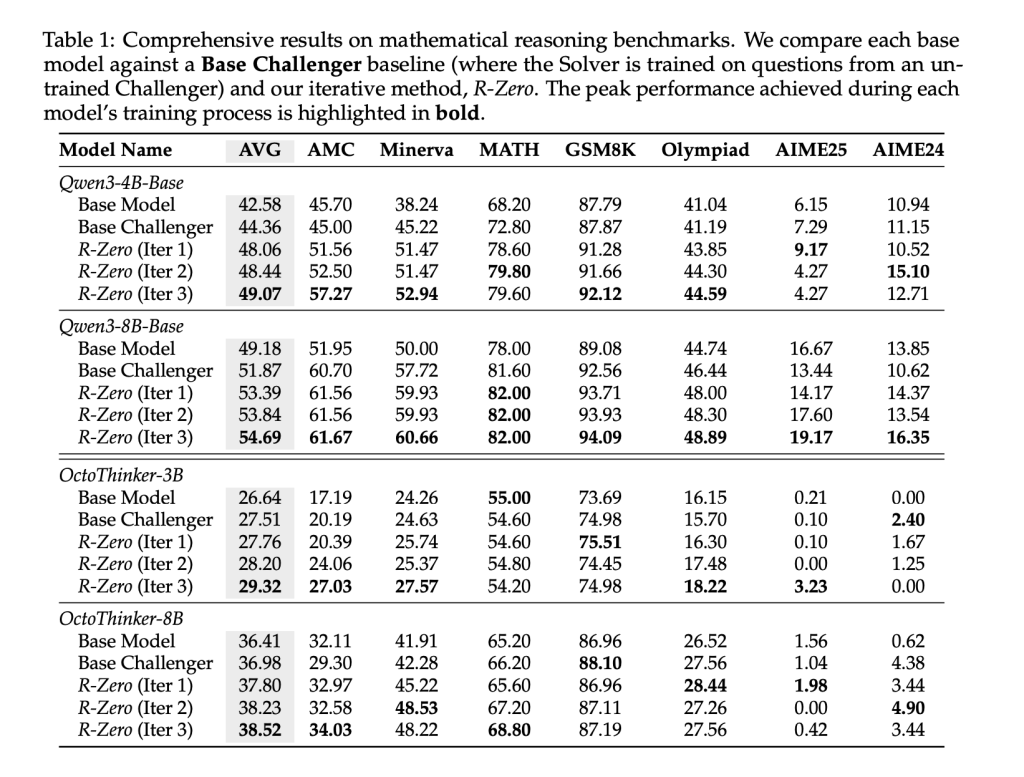
R-Zero was evaluated using seven rigorous mathematical benchmarks, including AMC, Minerva, MATH-500, GSM8K, Olympiad-Bench, and AIME competitions. Compared with the base model and non-trained Challenger baseline, three iterations of R-Zero led to substantial improvements in reasoning accuracy across all model sizes and architectures (e.g., Qwen3-8B-Base improved from 49.18 to 54.69 average score after three iterations).
General Reasoning Benchmarks
Crucially, R-Zero’s improvements generalize beyond math. Benchmarks including MMLU-Pro, SuperGPQA, and BIG-Bench Extra Hard (BBEH) show significant gains in general-domain reasoning accuracy (e.g., Qwen3-8B-Base’s overall average jumps from 34.49 to 38.73), demonstrating strong transfer effects.
Conclusion
R-Zero marks a major milestone toward self-sufficient, superhuman reasoning LLMs. Its fully autonomous co-evolutionary training pipeline offers not only strong empirical gains in reasoning but a new lens through which to view scalable, data-free AI development. Researchers and practitioners can experiment with this framework today, leveraging open-source tools to pioneer the next era of reasoning-centric language models.
Check out the Paper and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post R-Zero: A Fully Autonomous AI Framework that Generates Its Own Training Data from Scratch appeared first on MarkTechPost.