
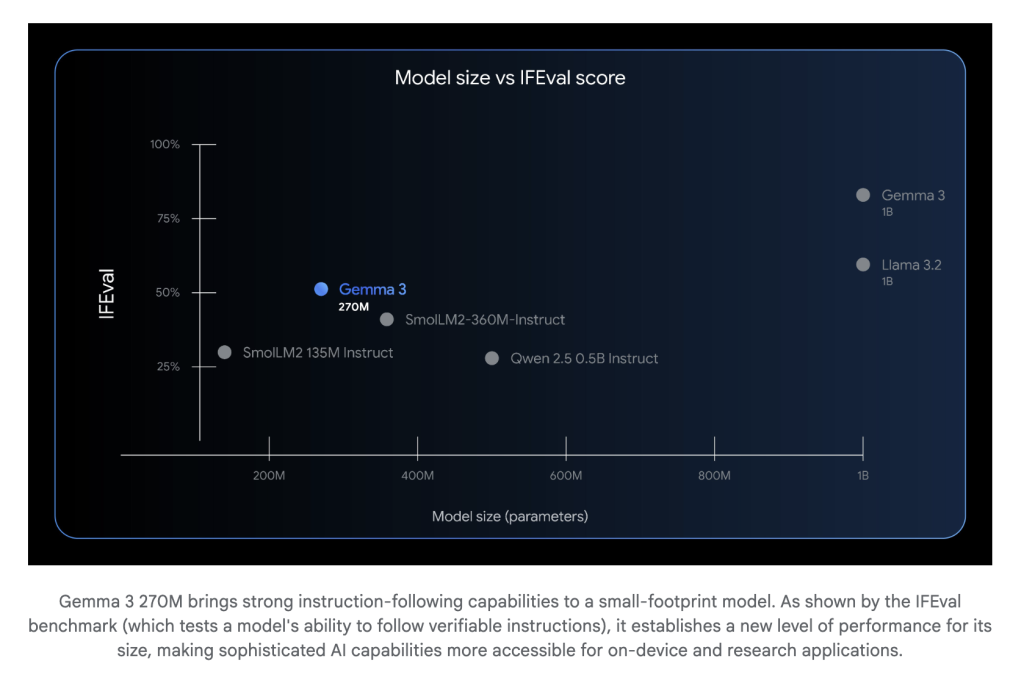
Google AI has expanded the Gemma family with the introduction of Gemma 3 270M, a lean, 270-million-parameter foundation model built explicitly for efficient, task-specific fine-tuning. This model demonstrates robust instruction-following and advanced text structuring capabilities “out of the box,” meaning it’s ready for immediate deployment and customization with minimal additional training.
Design Philosophy: “Right Tool for the Job”
Unlike large-scale models aimed at general-purpose comprehension, Gemma 3 270M is crafted for targeted use cases where efficiency outweighs sheer power. This is crucial for scenarios like on-device AI, privacy-sensitive inference, and high-volume, well-defined tasks such as text classification, entity extraction, and compliance checking.
Core Features
- Massive 256k Vocabulary for Expert Tuning:
Gemma 3 270M devotes roughly 170 million parameters to its embedding layer, supporting a huge 256,000-token vocabulary. This allows it to handle rare and specialized tokens, making it exceptionally fit for domain adaptation, niche industry jargon, or custom language tasks. - Extreme Energy Efficiency for On-Device AI:
Internal benchmarks show the INT4-quantized version consumes less than 1% battery on a Pixel 9 Pro for 25 typical conversations—making it the most power-efficient Gemma yet. Developers can now deploy capable models to mobile, edge, and embedded environments without sacrificing responsiveness or battery life. - Production-Ready with INT4 Quantization-Aware Training (QAT):
Gemma 3 270M arrives with Quantization-Aware Training checkpoints, so it can operate at 4-bit precision with negligible quality loss. This unlocks production deployments on devices with limited memory and compute, allowing for local, encrypted inference and increased privacy guarantees. - Instruction-Following Out of the Box:
Available as both a pre-trained and instruction-tuned model, Gemma 3 270M can understand and follow structured prompts instantly, while developers can further specialize behavior with just a handful of fine-tuning examples.
Model Architecture Highlights
| Component | Gemma 3 270M Specification |
|---|---|
| Total Parameters | 270M |
| Embedding Parameters | ~170M |
| Transformer Blocks | ~100M |
| Vocabulary Size | 256,000 tokens |
| Context Window | 32K tokens (1B and 270M sizes) |
| Precision Modes | BF16, SFP8, INT4 (QAT) |
| Min. RAM Use (Q4_0) | ~240MB |
Fine-Tuning: Workflow & Best Practices
Gemma 3 270M is engineered for rapid, expert fine-tuning on focused datasets. The official workflow, illustrated in Google’s Hugging Face Transformers guide, involves:
- Dataset Preparation:
Small, well-curated datasets are often sufficient. For example, teaching a conversational style or a specific data format may require just 10–20 examples. - Trainer Configuration:
Leveraging Hugging Face TRL’s SFTTrainer and configurable optimizers (AdamW, constant scheduler, etc.), the model can be fine-tuned and evaluated, with monitoring for overfitting or underfitting by comparing training and validation loss curves. - Evaluation:
Post-training, inference tests show dramatic persona and format adaptation. Overfitting, typically an issue, becomes beneficial here—ensuring models “forget” general knowledge for highly specialized roles (e.g., roleplaying game NPCs, custom journaling, sector compliance). - Deployment:
Models can be pushed to Hugging Face Hub, and run on local devices, cloud, or Google’s Vertex AI with near-instant loading and minimal computational overhead.
Real-World Applications
Companies like Adaptive ML and SK Telecom have used Gemma models (4B size) to outperform larger proprietary systems in multilingual content moderation—demonstrating Gemma’s specialization advantage. Smaller models like 270M empower developers to:
- Maintain multiple specialized models for different tasks, reducing cost and infrastructure demands.
- Enable rapid prototyping and iteration thanks to its size and computational frugality.
- Ensure privacy by executing AI exclusively on-device, with no need to transfer sensitive user data to the cloud.
Conclusion:
Gemma 3 270M marks a paradigm shift toward efficient, fine-tunable AI—giving developers the ability to deploy high-quality, instruction-following models for extremely focused needs. Its blend of compact size, power efficiency, and open-source flexibility make it not just a technical achievement, but a practical solution for the next generation of AI-driven applications.
Check out the Technical details here and Model on Hugging Face. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
 Star us on GitHub
Star us on GitHub Sponsorship Details
Sponsorship DetailsThe post Google AI Introduces Gemma 3 270M: A Compact Model for Hyper-Efficient, Task-Specific Fine-Tuning appeared first on MarkTechPost.